
De juiste bescherming voor uw bedrijfsapplicaties
In onze meer dan ooit digitaal verbonden wereld vraagt de bescherming van uw data en het directe herstel van uw applicaties zonder dataverlies om een kosteneffectieve en betrouwbare databeschermingsstrategie. De IT-eisen veranderen snel, wat maakt dat het mogelijk moet zijn datacenters snel van bestemming te veranderen en te herconfigureren. Verschillende nieuwe beheertools inzetten is geen realistische optie. Bedrijven willen een business-continuity-oplossing die aan al hun eisen voldoet – van het beschermen van een klein aantal volumes en afzonderlijke applicaties tot de bescherming van grote clusters en omgevingen van meerdere locaties.
Replicatie van native apps versus storagereplicatie
Normaal gesproken beschikken de meeste bedrijfsdatabases en -applicaties over de technologie voor hun eigen replicatie, zowel synchroon als asynchroon. Tools voor datareplicatie zoals Oracle Data Guard en dergelijke werken alleen op afzonderlijke databases en hebben dus het voordeel dat de stand-by database continu in recoverymodus staat. In het geval van een calamiteit kan de stand-by database dan ook heel snel en makkelijk geactiveerd worden als nieuwe primaire database.
Een echte uitdaging wordt het als er een kleine bug in de softwarestack of de configuratie-instellingen zit, wat de hele stand-by database nutteloos maakt. Een bug kan onder andere ook de fail-over, de overige applicatieservers, middleware of de monitoringsystemen verstoren.
Desondanks hanteren veel bedrijven verschillende replicatiemechanismen voor verschillende applicaties. Zo gebruiken ze bijvoorbeeld een aparte tool voor Oracle, SQL server, MySQL, IBM DB2 enzovoorts, wat het overall IT-beheer voor de CXO – de chief experience officer – een complexe aangelegenheid maakt.
Een alternatief voor applicatiereplicatie is storage mirroring. Als de mirrors gesynchroniseerd zijn, is een fail-over in het geval van een calamiteit zeker mogelijk, omdat alle data dan beschikbaar is in de mirror. U kunt ook het proces van applicatieherstel en -opstart versnellen door automatische storagefail-over te configureren in plaats van een handmatige disaster recovery te doen. Bij een end-to-end disaster recovery kan het een paar minuten duren voordat storage devices op de disaster-recovery-servers zijn geïnstalleerd en de databases voor de remote dataset zijn opgeroepen.
Een kosteneffectieve oplossing voor uw disaster-recovery-probleem
Verschillende toonaangevende storageleveranciers bieden tegenwoordig bescherming op verschillende niveaus met extra hardware, maar de meeste van deze oplossingen zijn niet kosteneffectief en ook niet betrouwbaar genoeg voor relationele databases. Bovendien is het nut van een dure secundaire faciliteit voor belangrijke activiteiten als ontwikkeling, testen en analytics relatief beperkt.
De kosteneffectieve en betrouwbare MetroCluster- en SnapMirror-technologieën van NetApp zijn vanaf het allereerste begin ontworpen als business-continuity-tools (zoals disaster recovery, back-up- en herstelscenario’s). Hun architectuur is dusdanig ontworpen dat ze niet afhankelijk zijn van bepaalde hostplatform-hardware, besturingssystemen, drivers, databases, applicaties, bestandsystemen, volumebeheer of een andere component van de applicatiehost.
De eenmalig in te stellen oplossing MetroCluster beschermt kritische data continu en maakt data 24/7 beschikbaar. Nadat de instances van MetroCluster correct gefigureerd zijn, hoeft u ze alleen nog maar te monitoren en te beheren. Zodra de omgeving wordt uitgebreid met nieuwe applicaties en workloads, wordt de data automatisch gerepliceerd en beschermd – zonder verandermanagement of beheerkosten. MetroCluster kan op een aantal verschillende manieren geconfigureerd worden, afhankelijk van de omgeving zoals in onderstaande afbeelding te zien is. Met de laatste releases van ONTAP® storage kan MetroCluster IP ISL een afstand van maximaal 700 kilometer overbruggen met een maximale round-trip latency van 10 milliseconden.
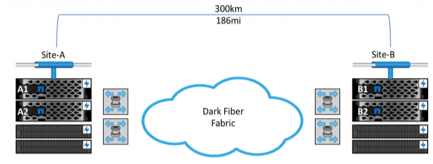
Figuur 1) MetroCluster-configuratie over fibre channel
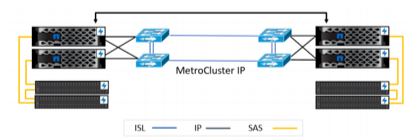
Figuur 2) MetroCluster-configuratie over IP
Figuur 3) MetroCluster-SDS
Opkomst van SnapMirror Synchronous
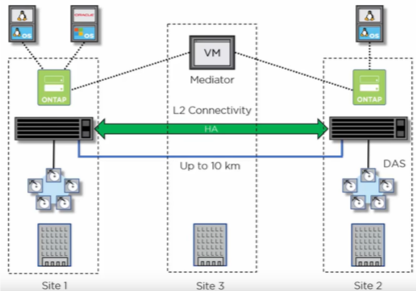
SnapMirror Synchronous (SM-S) van NetApp, geïntroduceerd in ONTAP 9.5, biedt de flexibiliteit om synchroon een subset volumes te beschermen in plaats van het hele cluster zoals in MetroCluster. Bovendien kan replicatie plaatsvinden tussen ONTAP-storagesystemen op verschillende platforms. SM-S kan bijvoorbeeld worden opgesteld tussen FAS en AFF, tussen FAS en ONTAP Select of tussen AFF en ONTAP Select.
Figuur 4) Een zero-RPO disaster-recovery-oplossing voor applicaties die gebruikmaken van SM-S
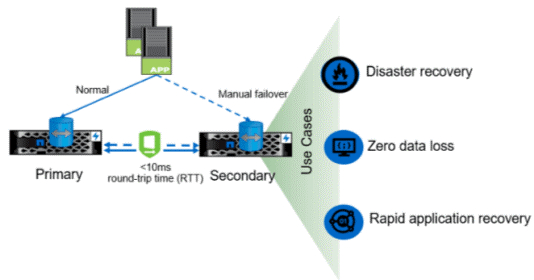
SM-S heeft geen nieuwe of speciale hardware, software of netwerkmogelijkheden nodig, wat maakt dat de totale kosten van de oplossing aanmerkelijk lager zijn. SM-S is geschikt voor relatief korte afstanden van maximaal 150 kilometer tussen ONTAP-storagesystemen. Met een round-triptijd van minder dan 10 milliseconden kun je een zero recovery point objective (RPO) bereiken en een near-zero recovery time objective (RTO).
SM-S-replicatie biedt twee soorten replicatie naar een fail-over-bestemming.
- StrictSync: in deze modus verstoort SM-S de I/O van de client als er een storing is in de synchrone replicatie naar de mirrorcopy.
- Sync: in deze modus behoudt SM-S de I/O van de client, zelfs na een storing in de synchrone replicatie naar de mirrorcopy. De mirrorstatus wordt op OutOfSync gezet, waarna automatisch een resync-proces wordt gestart om de relatie terug In Sync te brengen.
Voor relationele databases is het essentieel om afhankelijke schrijforderconsistentie te behouden wanneer de data in de storage verspreid is over meer dan één volume. Bij gebruik van de StrictSync-modus of -replicatie behoudt de I/O van de applicatie automatisch de schrijforderconsistentie. Het is echter cruciaal om de RTT-latency van het netwerk binnen de 10 milliseconden te houden.
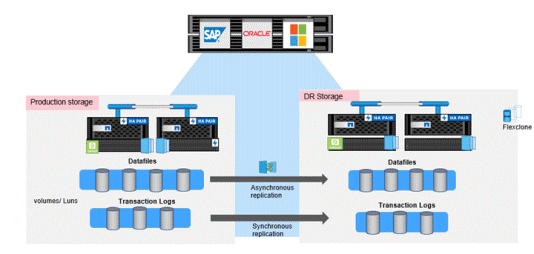
Figuur 5) Storage-indelingen voor zero-RPO disaster recovery
Een alternatieve methode is het asynchroon repliceren van databestandvolumes en het synchroon repliceren van transactielogs om een RPO van nul te behouden. Bekijk de video voor meer informatie over het mogelijk maken van synchrone replicatie voor Oracle-database-workloads en fail-over naar secundaire disaster-recovery-opslag.
Evenzo kunnen applicaties opnieuw naar hun primaire opslag gesynchroniseerd worden door een failback te doen tijdens het volgende service-window. Met drie kliks in de System Manager van NetApp is het gebeurd.
Storageoplossingen: eenvoudig en efficiënt
Het belangrijkste deel van een disaster-recovery-strategie is de evaluatie van de RPO en RTO, afhankelijk van de aard van de calamiteit. Het zou beperkt kunnen blijven tot alleen de storage, de databases of het netwerk, maar zou ook de hele locatie kunnen treffen.
Een databasereplicatietechnologie als Oracle Data Guard, Oracle GoldenGate, availability groups en andere opties zouden geschikt kunnen zijn bij een klein aantal kritische databases. Maar op deze manier een grootschalige infrastructuur beheren met honderden of soms duizenden databases met al hun middleware- en front-end-applicaties van dien is te complex en te duur.
Eenvoudige en efficiënte storageoplossingen voor disaster recovery zoals SnapMirror en MetroCluster zijn aanmerkelijk kosteneffectiever dan applicatiereplicatietools en kunnen makkelijk beheerd worden door IT-generalisten zonder dat daar extra kennis voor nodig is. Maak een vergelijking tussen beide synchrone replicatieoplossingen en beslis dan welke het best aan uw specifieke wensen voldoet.