
Drie indicatoren om netwerkperformance proactief te managen

Bedrijven worden steeds afhankelijker van hun netwerkperformance, zowel intern als voor webservices. Als servers of verbindingen niet beschikbaar zijn, of minder presteren, leidt dat tot verlies van klanten en omzet. Er zijn drie indicatoren om de netwerkperformance proactief te managen. Tonny van der Cammen, presales engineer Benelux van Flowmon Networks legt uit welke dat zijn en hoe u ze kunt toepassen.
Terminologie
Op netwerkgebied worden zoveel termen gebruikt dat het soms moeilijk is om door alle bomen het bos te blijven zien. “Als netwerkengineer was mijn belangrijkste KPI (key performance indicator) jarenlang MTTR (mean time to repair). Wanneer onze klanten netwerkgerelateerde issues ondervonden had ik een techniek nodig om de oorzaak zo snel mogelijk te kunnen achterhalen. Dat is alleen effectief mogelijk als het verkeer van laag 2 t/m 7 inzichtelijk is. Flowdata biedt dat inzicht (NetFlow/IPFIX) met als belangrijkste KPI’s: Round Trip Time (RTT), Server Response Time (SRT) en Jitter. Welke voordelen bieden deze indicatoren en in hoeverre vullen ze elkaar aan bij het voorkomen van performanceverliezen en downtime?
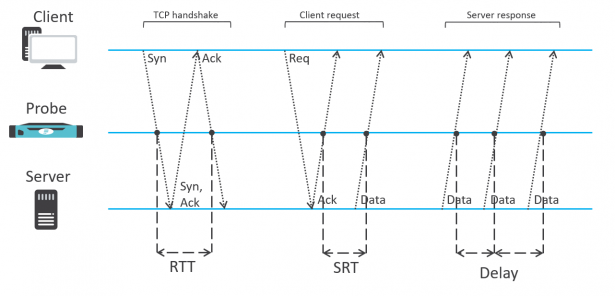
Fundering performancemonitoring
Network Performance Monitoring (NPM) is een methodiek om de oorzaak van performanceproblemen gerelateerd aan netwerkverkeer te achterhalen door twee belangrijke indicatoren passief te observeren, te weten RTT en SRT. RTT is de tijd waarin een datapakket wordt verzonden van de client naar de server en terug, ook wel netwerkvertraging genoemd. SRT is de tijd tussen een verzoek aan de applicatieserver en de tijd dat de server het eerste datapakket verstuurt. Bij NPM wordt ook onderscheid gemaakt tussen issues op het gebied van datatransmissie (netwerkvertragingen) en het gebruik van applicaties. Daardoor wordt het tevens duidelijk welk team of collega moet worden benaderd voor het oplossen ervan, omdat de impact en omvang volledig inzichtelijk worden.
Round Trip Time
RTT is een belangrijke waarde voor het beoordelen en managen van de netwerkperformance. Meestal is deze minder dan 1 ms (of enkele tientallen microseconden), omdat datapakketten in een lokaal netwerk of datacenter maar korte afstanden hoeven af te leggen en de apparatuur amper vertraging veroorzaakt. Wat betekent het dan als je een RTT van honderden milliseconden meet? De hoofdoorzaak daarvan is vrijwel altijd het netwerk, omdat een applicatie geen invloed heeft op de TCP-handshake. Deze maakt namelijk deel uit van de TCP/IP-stack die in het besturingssysteem zelf is geïmplementeerd. Er zou dus een storing in het besturingssysteem zelf nodig zijn om deze indicator te beïnvloeden, wat in de praktijk zelden voorkomt.
Veroorzakers RTT-vertraging
- Overbelasting van netwerkapparatuur, vooral routers: hoge pakketsnelheden beïnvloeden de buffers waar pakketten moeten wachten tot ze worden verzonden. QoS kan helpen om kritische services te prioriteren, maar een DDoS-aanval kan leiden tot netwerkcongestie en hogere waarden van RTT.
- Remote clients: applicaties kunnen traag reageren zonder dat er een netwerkprobleem is. Een RTT van 500ms over een VPN-verbinding vanuit thuis met een datacenter betekent dat het verzenden van pakketten een halve seconde duurt, wat gebruikers natuurlijk als traag kunnen ervaren.
- Cloud-applicaties: vergelijkbaar met de remote clients kan het migreren van applicaties van de bedrijfsserver naar de cloud tot ‘tragere’ prestaties leiden. Applicatieverkeer dat via het publieke Internet verloopt heeft namelijk al gauw een RTT van 100 ms (versus misschien 10 ms binnen het bedrijfsnetwerk). Als oplossing daarvoor gebruiken SaaS-providers Content Delivery Networks (CDN) en proxyservers om zowel de applicatie dichterbij hun klanten te hosten als de vertraging te reduceren. Om dezelfde reden gebruikten grote bedrijven dedicated verbindingen tussen de eigen infrastructuur en de cloud-serviceprovider. Analyses van het cloud-verkeer tonen vaak vertragingen in de RTT aan die buiten de scope van de applicatie-provider vallen.
Ethernet versus wifi
Vrijwel iedereen denkt dat een wifi-verbinding meer netwerkvertraging heeft dan een bekabelde aansluiting. Is dat ook zo en wat is het echte verschil? Naar mijn ervaring is het gangbare verschil zo’n 10 ms, dus wifi is gemiddeld 10ms trager dan een bekabelde ethernet-verbinding, onder ideale praktijkomstandigheden. In werkelijkheid komen er echter grotere verschillen voor omdat wifi last kan hebben van omgevingsfactoren, waaronder de interferentie van verschillende wifi-netwerken die dezelfde frequentie gebruiken.
Vertraging door snelheidsverschillen
Netwerkvertraging kan Tevens worden veroorzaakt door apparatuur met verschillende poortsnelheden. Bijvoorbeeld een 10G backbone waarmee servers via een 1G-uplink verbonden zijn. Als een groot aantal clients netwerkverkeer genereren dat de 1G capaciteit overschrijdt, leiden verzadigde switchbuffers tot verlies van datapakketten. Deze pakketten worden weliswaar automatisch opnieuw verzonden, maar alle applicatiegebruikers ervaren dit proces als een netwerkvertraging.
Server Response Time
SRT is een belangrijke indicator voor het beoordelen en managen van de netwerkperformance, gerelateerd aan de applicatie. Deze waarde is het verschil tussen de voorspelde observatietijd van het ACK-pakket van de server (op basis van de observatietijd van het clientrequest en gemeten RTT-waarde) en de werkelijke serverresponse. Het meten hiervan is niet alleen te baseren op observatie van een ACK-pakket van de server, omdat deze wellicht is samengevoegd met het antwoord van de server. Het versturen van de ACK samen met het eerste responsepakket leidt tot een SRT van 0 waarde, wat niet is wat we willen meten. Verder beperkt een SRT-meting zich niet alleen tot TCP-verkeer, omdat er ook UDP-verkeer te meten is.
Flowmon biedt ook een SRT-meting van DNS-verkeer, waarbij de cliënt en server worden onderscheiden op basis van de vraag of 53 de bronpoort (server) of bestemmingspoort (client) is. De gemeten serverresponse is het tijdsverschil tussen de observatietijden van het verzoek van de client en het antwoord van de server. SRT voorziet in een performancemeting voor de hele applicatie, per applicatieserver, per client netwerkdeel of zelfs individuele clients. Daardoor zijn relaties te ontdekken tussen de applicatieperformance en bepaalde clients op bepaalde momenten van de dag. In combinatie met de RTT-waarde is eenduidig te bepalen of het performanceverlies door een netwerk- of applicatieprobleem wordt veroorzaakt.
Jitter
Jitter is een indicator om onregelmatigheden in het netwerkverkeer te ontdekken door variaties in de vertragingen tussen verschillende datapakketten te berekenen. Onder ideale omstandigheden is de vertraging constant, waardoor de jitter nul is. In de werkelijkheid komt een jitter-waarde van 0 niet voor, omdat veel variabelen het netwerkverkeer beïnvloeden. Waarom moeten we eigenlijk jitter meten? Jitter is een kritische waarde voor het beoordelen van realtime netwerktoepassingen, zoals videostreaming en conferentiegesprekken. Maar ook voor het downloaden van bestanden, zoals het ISO-bestand voor een Linux-distributie vanaf de mirror-server. Als daarbij jitter optreedt is het wellicht een onstabiele verbinding.
Conclusie
Netwerkbeheerders die de NPM-indicatoren gebruiken kunnen zowel de netwerkperformance verbeteren als bijdragen aan applicatie-optimalisaties. Als gevolg daarvan krijgt iedereen een betere gebruikerservaring. Continu monitoren van NPM-indicatoren helpt problemen in netwerkverbindingen en applicaties sneller te identificeren en te verhelpen, misschien al voor gebruikers er hinder van ondervinden. Verder is historische data over de netwerkprestaties (RTT, SRT, Jitter) waardevol bij het voorspellen van toekomstige behoeften (capaciteitsplanning) en het zien aankomen van incidenten. Een wekenlang toenemende SRT voor interne bedrijfsapplicaties wijst bijvoorbeeld op overbelasting van de applicatieserver, wat makkelijk te verhelpen is voordat SLA-afspraken worden geschonden. Onder andere door extra capaciteit vrij te maken voor kritische applicaties, of een multi-server architectuur met load balancing te introduceren. Kortom, realtime inzicht in de NPM-indicatoren RTT, SRT en Jitter is voor elke netwerkbeheerder tegenwoordig onontbeerlijk.