
Vier misverstanden over flow data

Gegevens over netwerkverkeer - denk aan NetFlow- of IPFIX-data - werden tot voor kort vooral gebruikt in de telecom-wereld voor capaciteitsplanning, financiële verrekening van het gebruik van een netwerk en bijvoorbeeld bij DDoS-aanvallen. IT-afdelingen lijken nu echter ook de mogelijkheden van dit soort ‘flow data’ te ontdekken.
Al moeten dan nog wel een aantal misverstanden over flow-technologie uit de weg worden geruimd, meent Artur Kane van Flowmon.
Misverstand #1: Flow data is onnauwkeurig
Onder ‘flow data’ verstaan we gegevens over het netwerkverkeer die gegenereerd wordt aan de hand van protocollen als NetFlow en IPFIX. Netwerkbeheerders zijn vaak van mening dat de data die hierbij wordt voortgebracht in feite gesampled is en daarmee dus niet nauwkeurig. Dit klopt niet. Flow data via NetFlow en IPFIX is niet gesampled.
NetFlow en IPFIX worden vaak verward met sFlow en NetFlow Lite. Dit zijn twee protocollen die we vroeger vooral tegenkwamen in netwerkapparatuur voor het mkb. Deze standaarden zijn echter inmiddels achterhaald en kunnen beter niet meer gebruikt worden. Alle grote aanbieders van netwerkapparatuur leveren inmiddels routers en switches die op basis van NetFlow en IPFIX in staat zijn niet-gesamplede en zeer nauwkeurige statistieken over het netwerkverkeer te exporteren.
Met als gevolg dat de hoeveelheid flow data die beschikbaar is ook enorm is toegenomen. Alle belangrijke fabrikanten van firewalls maken het eveneens mogelijk om netwerkstatistieken te exporteren, terwijl de bekende virtualisatieplatformen het mogelijk maken om inzicht te krijgen in al deze gegevens. Zelfs low-cost apparatuur - denk bijvoorbeeld aan routers van Mikrotik - kunnen nauwkeurige statistieken leveren.
Een professionele analyse-tool - ook wel een ‘collector’ genoemd - visualiseert al deze data en toont daarbij het east-west dataverkeer in het netwerk. Hierdoor verkrijgen functionarissen als netwerkbeheerders en IT-managers inzicht in het gebruik dat gemaakt wordt van individuele uplinks in de diverse locaties. Vergeet hierbij echter niet dat een analyse en visualisatie van flow data misschien nog wel de meeste waarde oplevert bij troubleshooting bij storingen of incidenten in het netwerk.
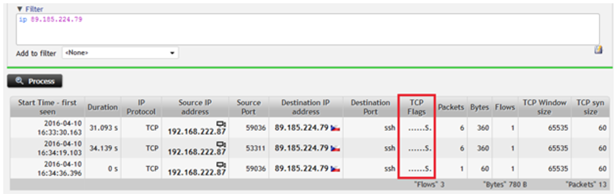
Neem het volgende voorbeeld (zie figuur 1). Een gebruiker ondervindt problemen bij het leggen van een verbinding met een server via SSH. Als we in zo’n geval gebruikmaken van flow data, dan kunnen we heel gemakkelijk vaststellen dat er - bijvoorbeeld - geen respons is van de server. En kunnen we op zoek gaan naar de oorzaak. Is bijvoorbeeld een bepaald gedeelte van het netwerk niet beschikbaar? Is de server down? Is er sprake van configuratiefouten? De veelheid aan mogelijke oorzaken kan dan bijvoorbeeld worden teruggebracht tot ‘de service is niet actief’ of ‘de communicatie wordt tegengehouden door een firewall’. Hierdoor kan de zogeheten ‘meantime to resolve’ (MTTR) enorm worden gereduceerd.
Misverstand #2: Flow data geeft alleen inzicht in lagen 2 of 3
Dat is correct voorzover we het hebben over het oorspronkelijke idee achter flow data. Maar we zijn inmiddels een flinke stap verder.
Bij flow data hebben we het over een datapakketje dat door het netwerk gaat met een identificatie die bestaat uit het IP-adres waar het vandaan komt, het IP-adres waar het naartoe gaat, de poort bij de bron, de poort op het gewenste adres en het protocol. Op basis van deze informatie worden packets geaggregeerd tot zogeheten ’flow records’ die een beeld schetsen van de hoeveelheid verzonden data, het aantal packets en additionele informatie die afkomstig is uit de netwerk- en transportlaag.
Sinds circa 5 jaar wordt deze data echter verrijkt met gegevens die afkomstig zijn uit de applicatielaag. Deze aanpak is in eerste instantie door Flowmon ontwikkeld en inmiddels door talloze aanbieders overgenomen. Hierdoor is het nu mogelijk om ook een goed inzicht te verkrijgen in de applicatieprotocollen - dus HTTP, DNS en bijvoorbeeld DHCP. Dit heeft grote en positieve gevolgen voor troubleshooting.
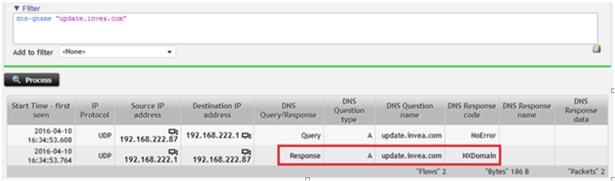
Wederom een voorbeeld (zie figuur 2). Een gebruiker klaagt over een service die niet reageert. Op basis van een analyse van traditionele gegevens over het netwerkverkeer zien we het verkeerspatroon. Evenals details over individuele connecties die door de computer van de gebruiker tot stand zijn gebracht. Alles lijkt hierbij in orde te zijn. Maar tegelijkertijd zien we geen verkeer naar de service. Door gebruik te maken van een tool als Flowmon’s flow data engine kunnen we gebruikmaken van de verrijkte flow data. Hiermee kunnen we bepalen waar het probleem precies zit.
In dit voorbeeld blijkt de naam van de service niet goed te zijn geconfigureerd in de DNS-service. Deze geeft hierdoor als antwoord ‘NXDOMAIN’, wat aangeeft dat de gevraagde domeinnaam niet bestaat en het daarbij behorende IP-adres niet kan worden verschaft. Met andere woorden: er wordt geen sessie met de service tot stand gebracht.
Misverstand #3: Flow data zegt niets over prestaties
Tot nu toe hebben we het vooral gehad over troubleshooting. Het monitoren van de prestaties van het netwerk is echter ook van cruciaal belang. Netwerk monitoring wordt niet uitsluitend verzorgd door tools voor packet capturing. Informatie over de netwerkprestaties kunnen eenvoudig uit packet data worden gehaald en worden geëxporteerd als onderdeel van de flow-statistieken. Prestatie-indicatoren als RTT (round trip time), SRT (server response time), jitters of het aantal hertransmissies zijn voor alle netwerkverkeer beschikbaar. Het maakt hierbij niet uit welk applicatieprotocol wordt gebruikt.
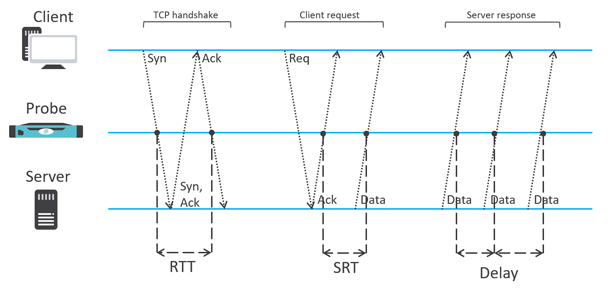
Deze aanpak is gezien de vele voordelen inmiddels geadopteerd door aanbieders als Cisco. Deze aanbieder biedt dit soort gegevens als onderdeel van zijn AVC (application visibility and control) en ART (application response time) extensies. Dit betekent dat de netwerkbeheerder inzicht heeft in de prestaties van alle in gebruik zijnde applicaties - ook als het gaat om private of public cloud-omgevingen. Hoe dit werkt is zichtbaar in figuur 3.
Misverstand #4: Flow is geen alomvattende tool voor netwerk performance en diagnose
Volgens Gartner is het primaire doel van tools voor NPMD (network performance monitoring and diagnostics) het bieden van prestatiegegevens door gebruik te maken van alle beschikbare data over packets. Ook dienen NPMD-tools te beschikken over faciliteiten voor het onderzoeken van netwerkproblemen door het analyseren van het traject dat packets door het netwerk afleggen.
Hebben we daarbij een oplossing voor packet capture nodig? Nee, ik denk het niet. Verrijkte flow data biedt accurate statistieken over het netwerkverkeer, geeft inzicht in laag 7 ofwel de applicatieprotocollen en verschaft meetwaarden over de prestaties van het netwerk. Met andere woorden: verrijkte flow data biedt alles wat we nodig hebben voor NPMD-toepassingen.
Met de opkomst van versleuteld netwerkverkeer, heterogene netwerkomgevingen en almaar toenemende snelheden is het onvermijdelijk dat flow data de dominante aanpak op het gebied van NPMD gaat worden. Alleen al de explosie in bandbreedte wordt een enorme uitdaging voor legacy packet-oplossingen.
Laten we wederom naar een voorbeeld kijken. Een netwerk backbone met een capaciteit van 10G heeft 108 TB aan opslagcapaciteit nodig om alle netwerkverkeer gedurende een periode van 24 uur te kunnen volgen. Dit is natuurlijk een enorme storage-capaciteit maar we hebben bij een legacy-aanpak nu eenmaal veel opslagruimte nodig voor het verzamelen, vastleggen en analyseren van alle netwerkverkeer. Hierdoor wordt een legacy-aanpak extreem duur.
Wie kiest voor een aanpak op basis van flow data heeft slechts een fractie van deze opslagcapaciteit nodig. Ga uit van 250 GB. Daarmee is een netwerkbeheerder in staat om historische gegevens over een periode van 30 dagen vast te leggen op een collector die voorzien is van een storage-ruimte van 8 TB. Dat is dus slechts een fractie van wat een traditionele oplossing nodig heeft.
Terug naar Gartner’s definitie van MPMD. Hoe zit het nu in een situatie waarin een probleem met een niet-ondersteund applicatieprotocol moet worden onderzocht? Ook dan kan flow data helpen, is onze ervaring. Wie de eerder genoemde probe in het netwerk heeft opgenomen, heeft daarmee toegang tot de volledige gegevens over een packet. In zo’n geval is het verstandig om allereerst alle metadata uit de packets te extraheren. Om vervolgens de probe opdracht te geven een packet capture te doen. Hierbij kunnen we nauwkeurig aangeven welke packets we willen vastleggen en gedurende welke periode. Hierdoor kunnen we de hoeveelheid data die vastgelegd dient te worden sterk terugbrengen - ook in een 10G-netwerkomgeving.
Hoe verder?
Voorheen werd flow data nog wel eens gezien als het spreekwoordelijke ‘speeltje’ van netwerkbeheerders. Daar is tegenwoordig geen sprake meer van. Flow data biedt een zeer professionele oplossing voor het op een zeer fijnmazige manier analyseren en oplossen van storingen of incidenten in het netwerk. Ook kunnen hiermee problemen rond foutieve configuraties worden opgelost. En - net als bij telco’s voorheen - biedt flow data een prima basis voor capaciteitsplanning.
De voordelen ten opzichte van packet capture tools die continu netwerkverkeer vastleggen zijn groot te noemen. De schaalbaarheid is veel beter doordat veel minder opslagcapaciteit nodig is. Hierdoor kunnen veel grotere netwerken worden gemonitored dan met continuous packet capture tools. Ook zijn flow data tools flexibel en erg eenvoudig te gebruiken. Hierdoor kunnen netwerkbeheerders kostbare tijd besparen, de MTTR drastisch verkorten. Waarmee zij de beheerkosten van het netwerk waarvoor zij verantwoordelijk zijn verder kunnen terugbrengen.
Interessant aan het gebruik van flow data is dat het in feite vier mogelijkheden in zich verenigt: netwerk operations, performance monitoring, trouble shooting plus analyse van het gedrag van het netwerk. Met deze laatste faciliteit kunnen ook security-taken worden uitgevoerd. Denk aan het vaststellen van inbreuken op het netwerk, Advanced Persistent Threats (APT), aanvallen op het netwerk en dergelijke. Met de opkomst van trends als cloud, Internet of Things, Software Defined Networking en het almaar verder toenemen van bandbreedte voorzie ik een sterk toenemend gebruik van flow data.
Artur Kane is technology evangelist bij Flowmon